CVPR 2026
FMMC: Foundation Models for
Material Classification
Harnessing the Power of Foundation Models for Accurate Material Classification
∗ Equal contribution

Abstract
Material classification has emerged as a critical task in computer vision and graphics, supporting the assignment of accurate material properties to a wide range of digital and real-world applications. While traditionally framed as an image classification task, this domain faces significant challenges due to the scarcity of annotated data, limiting the accuracy and generalizability of trained models. Recent advances in vision-language foundation models (VLMs) offer promising avenues to address these issues, yet existing solutions leveraging these models still exhibit unsatisfying results in material recognition tasks.
In this work, we propose a novel framework that effectively harnesses foundation models to overcome data limitations and enhance classification accuracy. Our method integrates two key innovations: (a) a robust image generation and auto-labeling pipeline that creates a diverse and high-quality training dataset with material-centric images, and automatically assigns labels by fusing object semantics and material attributes in text prompts; (b) a prior incorporation strategy to distill information from VLMs, combined with a joint fine-tuning method that optimizes a pre-trained vision foundation model alongside VLM-derived priors, preserving broad generalizability while adapting to material-specific features. Extensive experiments demonstrate significant improvements on multiple datasets.
Method
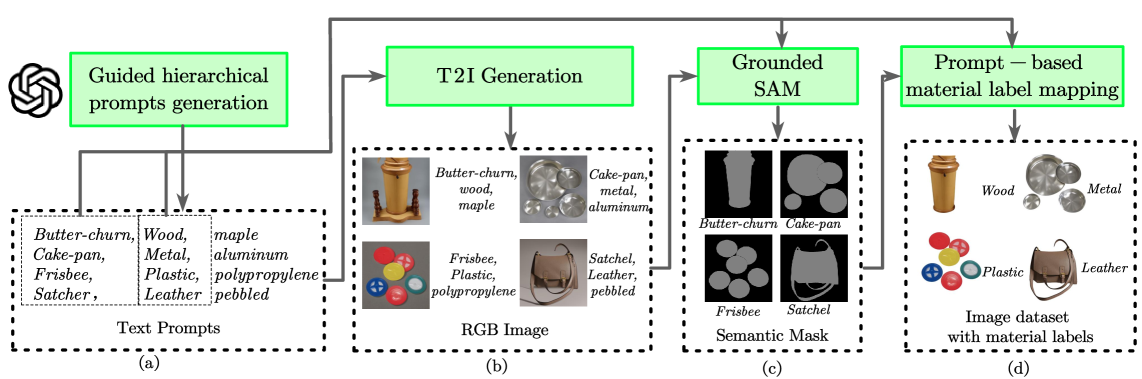
Figure 2. Dataset generation workflow. Our pipeline synthesizes labeled material images through: (a) hierarchical prompt engineering with LLM-guided plausibility filtering, (b) diffusion-based image generation with model selection, (c) semantic mask extraction via Grounding DINO and Grounded SAM, and (d) region-aware material label assignment.
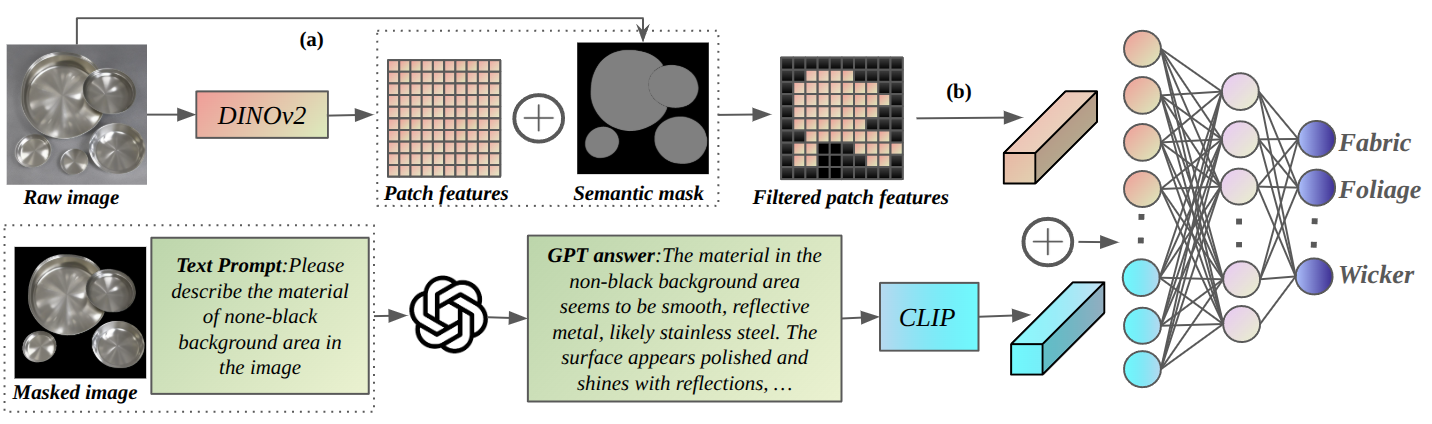
Figure 4. The dual-stream architecture of FMMC. The visual stream (DINOv2) extracts dense patch features with mask-based pooling, while the language stream encodes GPT-4v–generated material descriptions via CLIP. Both streams are fused by a lightweight MLP projection head for final material category prediction.
01
Synthetic Data Generation
Hierarchical prompt engineering—validated by ChatGPT for semantic plausibility of object–material pairings—drives Stable Diffusion v2.1 to synthesize diverse, balanced, and material-centric training images at scale, addressing the fundamental data scarcity challenge in material recognition.
02
Automatic Annotation
Grounding DINO localizes material regions in synthesized images, and Grounded SAM produces precise instance masks that are mapped to material categories. This fully automatic pipeline achieves 98% annotation accuracy, eliminating the need for costly manual labeling.
03
Dual-Stream Fusion
A visual stream leverages DINOv2 to extract dense patch-level features with mask-based pooling, while a language stream encodes GPT-4v–generated material descriptions using CLIP into semantic embeddings. Both streams are integrated by a lightweight MLP projection head for classification.
04
Joint Fine-Tuning with VLM Priors
A pre-trained vision foundation model is jointly optimized alongside VLM-derived priors in a tailored fine-tuning strategy that preserves broad visual generalizability while adapting specifically to material-discriminative features.
Results
Quantitative Comparison
FMMC is evaluated on three standard material recognition benchmarks: FMD (10 categories), DMS-test (21 categories), and Google-test (21 categories). Our method substantially outperforms MatSim and zero-shot VLM baselines (CLIP, GPT-4v) across all benchmarks. Zero-shot baselines reach only 38–43% accuracy on DMS-test, highlighting the limitation of foundation models without task-specific fine-tuning.
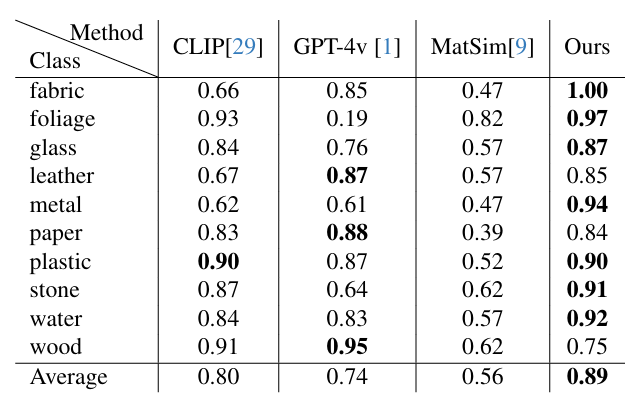
Table 1. Comparison with state-of-the-art methods on the FMD dataset (10 classes). All values denote classification accuracy. Best result per row in bold. FMMC achieves the highest average accuracy of 0.89.
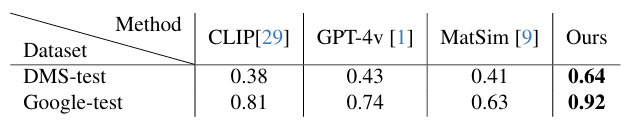
Table 2. Comparison on DMS-test (21 classes) and Google-test (21 classes). All values denote classification accuracy. FMMC achieves 0.64 on DMS-test and 0.92 on Google-test, outperforming all baselines.
Ablation Studies
We ablate three key design dimensions: (1) synthetic dataset quality vs. real DMS training data, (2) the contribution of each stream in the dual-stream architecture, and (3) the choice of vision backbone. Results confirm that our synthetic data generalizes better to unseen distributions, both streams contribute complementary signals, and DINOv2 with head-only fine-tuning is the superior backbone choice.

Table 3. Comparison of material classification with DMS dataset (mIoU | mAcc). Our synthetic data achieves better cross-domain generalization on Google-test and FMD, while DMS training data shows higher in-domain DMS-test scores.
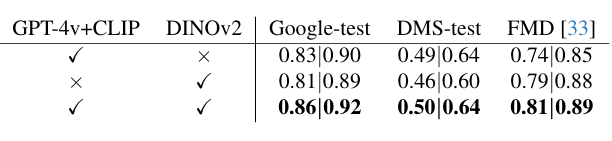
Table 4. Influence of the language stream (GPT-4v + CLIP) and vision stream (DINOv2) on material classification (mIoU | mAcc). Combining both streams yields the best performance across all three benchmarks.
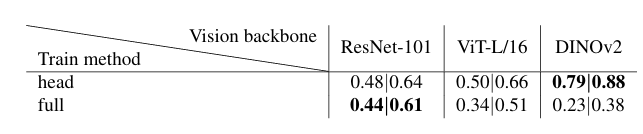
Table 5. Comparison across vision backbones (mIoU | mAcc). DINOv2 with head-only fine-tuning substantially outperforms ResNet-101 and ViT-L/16 under both head-only and full fine-tuning settings.
Qualitative Results

Resources
Citation
If you find this work useful in your research, please consider citing:
@inproceedings{lin2026fmmc,
title = {Harnessing the Power of Foundation Models for Accurate Material Classification},
author = {Lin, Qingran and Yang, Fengwei and Zhu, Chaolun},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2026}
}
ⓘ Official CVPR 2026 proceedings details (page numbers, DOI) will be updated after publication.